
我愛你,你是自由的。
There are many Python machine learning resources freely available online. Where to begin? How to proceed? Go from zero to Python machine learning hero in 7 steps!
By Matthew Mayo.
Getting started. Two of the most de-motivational words in the English language. The first step is often the hardest to take, and when given too much choice in terms of direction it can often be debilitating.

Where to begin?
This post aims to take a newcomer from minimal knowledge of machine learning in Python all the way to knowledgeable practitioner in 7 steps, all while using freely available materials and resources along the way. The prime objective of this outline is to help you wade through the numerous free options that are available; there are many, to be sure, but which are the best? Which complement one another? What is the best order in which to use selected resources?
Moving forward, I make the assumption that you are not an expert in:
▪ Machine learning
▪ Python
▪ Any of Python’s machine learning, scientific computing, or data analysis libraries
It would probably be helpful to have some basic understanding of one or both of the first 2 topics, but even that won’t be necessary; some extra time spent on the earlier steps should help compensate.
If we intend to leverage Python in order to perform machine learning, having some base understanding of Python is crucial. Fortunately, due to its widespread popularity as a general purpose programming language, as well as its adoption in both scientific computing and machine learning, coming across beginner’s tutorials is not very difficult. Your level of experience in both Python and programming in general are crucial to choosing a starting point.
First, you need Python installed. Since we will be using scientific computing and machine learning packages at some point, I suggest that you install Anaconda. It is an industrial-strength Python implementation for Linux, OSX, and Windows, complete with the required packages for machine learning, including numpy, scikit-learn, and matplotlib. It also includes iPython Notebook, an interactive environment for many of our tutorials. I would suggest Python 2.7, for no other reason than it is still the dominant installed version.
learn-pythonIf you have no knowledge of programming, my suggestion is to start with the following free online book, then move on to the subsequent materials:
▪ Python The Hard Way by Zed A. Shaw
If you have experience in programming but not with Python in particular, or if your Python is elementary, I would suggest one or both of the following:
▪ Google Developers Python Course (highly recommended for visual learners)
▪ An Introduction to Python for Scientific Computing (from UCSB Engineering) by M. Scott Shell (a great scientific Python intro ~60 pages)
And for those looking for a 30 minute crash course in Python, here you go:
▪ Learn X in Y Minutes (X = Python)
Of course, if you are an experienced Python programmer you will be able to skip this step. Even if so, I suggest keeping the very readable Python documentation handy.
KDnuggets’ own Zachary Lipton has pointed out that there is a lot of variation in what people consider a “data scientist.” This actually is a reflection of the field of machine learning, since much of what data scientists do involves using machine learning algorithms to varying degrees. Is it necessary to intimately understand kernel methods in order to efficiently create and gain insight from a support vector machine model? Of course not. Like almost anything in life, required depth of theoretical understanding is relative to practical application. Gaining an intimate understanding of machine learning algorithms is beyond the scope of this article, and generally requires substantial amounts of time investment in a more academic setting, or via intense self-study at the very least.
The good news is that you don’t need to possess a PhD-level understanding of the theoretical aspects of machine learning in order to practice, in the same manner that not all programmers require a theoretical computer science education in order to be effective coders.
Andrew Ng’s Coursera course often gets rave reviews for its content; my suggestion, however, is to browse the course notes compiled by a former student of the online course’s previous incarnation. Skip over the Octave-specific notes (a Matlab-like language unrelated to our Python pursuits). Be warned that these are not “official” notes, but do seem to capture the relevant content from Andrew’s course material. Of course, if you have the time and interest, now would be the time to take Andrew Ng’s Machine Learning course on Coursera.
▪ Unofficial Andrew Ng course notes
There all sorts of video lectures out there if you prefer, alongside Ng’s course mentioned above. I’m a fan of Tom Mitchell, so here’s a link to his recent lecture videos (along with Maria-Florina Balcan), which I find particularly approachable:
▪ Tom Mitchell Machine Learning Lectures
You don’t need all of the notes and videos at this point. A valid strategy involves moving forward to particular exercises below, and referencing applicable sections of the above notes and videos when appropriate. For example, when you come across an exercise implementing a regression model below, read the appropriate regression section of Ng’s notes and/or view Mitchell’s regression videos at that time.
Alright. We have a handle on Python programming and understand a bit about machine learning. Beyond Python there are a number of open source libraries generally used to facilitate practical machine learning. In general, these are the main so-called scientific Python libraries we put to use when performing elementary machine learning tasks (there is clearly subjectivity in this):
▪ numpy - mainly useful for its N-dimensional array objects
▪ pandas - Python data analysis library, including structures such as dataframes
▪ matplotlib - 2D plotting library producing publication quality figures
▪ scikit-learn - the machine learning algorithms used for data analysis and data mining tasks
A good approach to learning these is to cover this material:
▪ Scipy Lecture Notes by Gaël Varoquaux, Emmanuelle Gouillart, and Olav Vahtras
This pandas tutorial is good, and to the point:
You will see some other packages in the tutorials below, including, for example, Seaborn, which is a data visualization library based on matplotlib. The aforementioned packages are (again, subjectively) the core of a wide array of machine learning tasks in Python; however, understanding them should let you adapt to additional and related packages without confusion when they are referenced in the following tutorials.
Now, on to the good stuff…
Python. Check.
Machine learning fundamentals. Check.
Numpy. Check.
Pandas. Check.
Matplotlib. Check.
The time has come. Let’s start implementing machine learning algorithms with Python’s de facto standard machine learning library, scikit-learn.
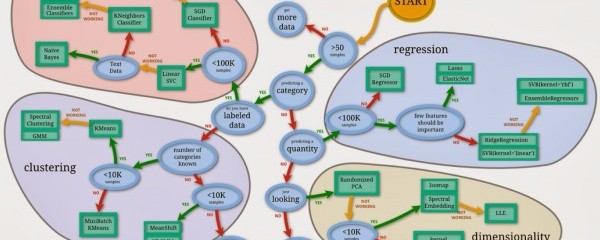
The scikit-learn flow chart.
Many of the following tutorials and exercises will be driven by the iPython (Jupyter) Notebook, which is an interactive environment for executing Python. These iPython notebooks can optionally be viewed online or downloaded and interacted with locally on your own computer.
▪ iPython Notebook Overview from Stanford
Also note that the tutorials below are from a number of online sources. All Notebooks have been attributed to the authors; if, for some reason, you find that someone has not been properly credited for their work, please let me know and the situation will be rectified ASAP. In particular, I would like to tip my hat to Jake VanderPlas, Randal Olson, Donne Martin, Kevin Markham, and Colin Raffel for their fantastic freely-available resources.
Our first tutorials for getting our feet wet with scikit-learn follow. I suggest doing all of these in order before moving to the following steps.
A general introduction to scikit-learn, Python’s most-used general purpose machine learning library, covering the k-nearest neighbors algorithm:
▪ An Introduction to scikit-learn by Jake VanderPlas
A more in-depth and expanded introduction, including a starter project with a well-known dataset from start to finish:
▪ Example Machine Learning Notebook by Randal Olson
A focus on strategies for evaluating different models in scikit-learn, covering train/test dataset splits:
▪ Model Evaluation by Kevin Markham
With a foundation having been laid in scikit-learn, we can move on to some more in-depth explorations of the various common, and useful, algorithms. We start with k-means clustering, one of the most well-known machine learning algorithms. It is a simple and often effective method for solving unsupervised learning problems:
▪ k-means Clustering by Jake VanderPlas
Next, we move back toward classification, and take a look at one of the most historically popular classification methods:
▪ Decision Trees via The Grimm Scientist
From classification, we look at continuous numeric prediction:
▪ Linear Regression by Jake VanderPlas
We can then leverage regression for classification problems, via logistic regression:
▪ Logistic Regression by Kevin Markham
We’ve gotten our feet wet with scikit-learn, and now we turn our attention to some more advanced topics. First up are support vector machines, a not-necessarily-linear classifier relying on complex transformations of data into higher dimensional space.
▪ Support Vector Machines by Jake VanderPlas
Next, random forests, an ensemble classifier, are examined via a Kaggle Titanic Competition walk-through:
▪ Kaggle Titanic Competition (with Random Forests) by Donne Martin
Dimensionality reduction is a method for reducing the number of variables being considered in a problem. Principal Component Analysis is a particular form of unsupervised dimensionality reduction:
▪ Dimensionality Reduction by Jake VanderPlas
Before moving on to the final step, we can take a moment to consider that we have come a long way in a relatively short period of time.
Using Python and its machine learning libraries, we have covered some of the most common and well-known machine learning algorithms (k-nearest neighbors, k-means clustering, support vector machines), investigated a powerful ensemble technique (random forests), and examined some additional machine learning support tasks (dimensionality reduction, model validation techniques). Along with some foundational machine learning skills, we have started filling a useful toolkit for ourselves.
We will add one more in-demand tool to that kit before wrapping up.
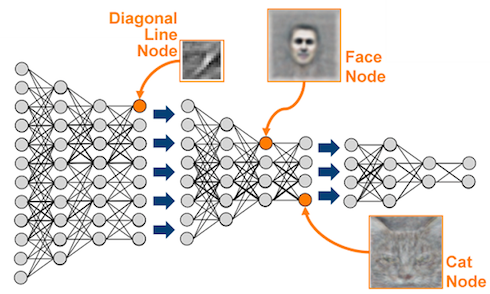
The learning is deep.
Deep learning is everywhere! Deep learning builds on neural network research going back several decades, but recent advances dating to the past several years have dramatically increased the perceived power of, and general interest in, deep neural networks. If you are unfamiliar with deep learning, KDnuggets has many articles detailing the numerous recent innovations, accomplishments, and accolades of the technology.
This final step does not purport to be a deep learning clinic of any sort; we will take a look at a few simple network implementations in 2 of the leading contemporary Python deep learning libraries. For those interested in digging deeper into deep learning, I recommend starting with the following free online book:
▪ Neural Networks and Deep Learning by Michael Nielsen
Theano is the first Python deep learning library we will look at. From the authors:
Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently.
The following introductory tutorial on deep learning in Theano is lengthy, but it is quite good, very descriptive, and heavily-commented:
▪ Theano Deep Learning Tutorial by Colin Raffel
The other library we will test drive is Caffe. Again, from the authors:
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors.
This tutorial is the cherry on the top of this article. While we have undertaken a few interesting examples above, none likely compete with the following, which is implementing Google’s #DeepDream using Caffe. Enjoy this one! After understanding the tutorial, play around with it to get your processors dreaming on their own.
▪ Dreaming Deep with Caffe via Google’s GitHub
I didn’t promise it would be quick or easy, but if you put the time in and follow the above 7 steps, there is no reason that you won’t be able to claim reasonable proficiency and understanding in a number of machine learning algorithms and their implementation in Python using its popular libraries, including some of those on the cutting edge of current deep learning research.
Bio: Matthew Mayo is a computer science graduate student currently working on his thesis parallelizing machine learning algorithms. He is also a student of data mining, a data enthusiast, and an aspiring machine learning scientist.
Related:
Top 20 Data Science MOOCs
60+ Free Books on Big Data, Data Science, Data Mining, Machine Learning, Python, R, and more
15 Mathematics MOOCs for Data Science