
我愛你,你是自由的。

機器學習算法太多了,分類、回歸、聚類、推薦、圖像識別領域等等,要想找到一個合適算法真的不容易,所以在實際應用中,我們一般都是采用啟發式學習方式來實驗。通常最開始我們都會選擇大家普遍認同的算法,諸如SVM,GBDT,Adaboost,現在深度學習很火熱,神經網絡也是一個不錯的選擇。假如你在乎精度(accuracy)的話,最好的方法就是通過交叉驗證(cross-validation)對各個算法一個個地進行測試,進行比較,然後調整參數確保每個算法達到最優解,最後選擇最好的一個。但是如果你只是在尋找一個“足夠好”的算法來解決你的問題,或者這裡有些技巧可以參考,下面來分析下各個算法的優缺點,基於算法的優缺點,更易於我們去選擇它。
在統計學中,一個模型好壞,是根據偏差(Bias)和方差(Variance)來衡量的,所以我們先來普及一下偏差和方差:
偏差:描述的是預測值(估計值)的期望E’與真實值Y之間的差距。偏差越大,越偏離真實數據。The bias is error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs (underfitting).
方差:描述的是預測值P的變化範圍,離散程度,是預測值的方差,也就是離其期望值E的距離。方差越大,數據的分布越分散。The variance is error from sensitivity to small fluctuations in the training set. High variance can cause overfitting: modeling the random noise in the training data, rather than the intended outputs.
模型的真實誤差是兩者之和,如下式:
如果是小訓練集,高偏差/低方差的分類器(例如,樸素貝葉斯NB)要比低偏差/高方差大分類的優勢大(例如,KNN),因為後者會過擬合。但是,隨著你訓練集的增長,模型對於原數據的預測能力就越好,偏差就會降低,此時低偏差/高方差分類器就會漸漸的表現其優勢(因為它們有較低的漸近誤差),此時高偏差分類器此時已經不足以提供准確的模型了。
當然,你也可以認為這是生成模型(混合高斯模型、樸素貝葉斯,隱馬爾科夫模型等)與判別模型(KNN、SVM、LR等)的一個區別。
在概率統計理論中, 生成模型(Generatve Model)是指能夠隨機生成觀測數據的模型,尤其是在給定某些隱含參數的條件下。它給觀測值和標註數據序列指定一個聯合概率分佈。在機器學習中,生成模型可以用來直接對數據建模(例如根據某個變量的概率密度函數進行數據採樣),也可以用來建立變量間的條件概率分佈。條件概率分佈可以由生成模型根據貝葉斯准測形成。
在機器學習領域判別模型(Discriminative Model)是一種對未知數據與已知數據
之間關係進行建模的方法。判別模型是一種基於概率理論的方法。已知輸入變量
,判別模型通過構建條件概率分佈
預測
。
與生成模型不同,判別模型不考慮與
間的聯合分佈。對於諸如分類和回歸問題,由於不考慮聯合概率分佈,採用判別模型可以取得更好的效果。而生成模型在刻畫複雜學習任務中的依賴關係方面則較判別模型更加靈活。大部分判別模型本身是監督學習模型,不易擴展用於非監督學習過程。實踐中,需根據應用的具體特性來選取判別模型或生成模型。
為什麼說樸素貝葉斯是高偏差低方差?
以下內容引自知乎:
首先,假設你知道訓練集和測試集的關系。簡單來講是我們要在訓練集上學習一個模型,然後拿到測試集去用,效果好不好要根據測試集的錯誤率來衡量。但很多時候,我們只能假設測試集和訓練集的是符合同一個數據分布的,但卻拿不到真正的測試數據。這時候怎麼在只看到訓練錯誤率的情況下,去衡量測試錯誤率呢?
由於訓練樣本很少(至少不足夠多),所以通過訓練集得到的模型,總不是真正正確的。(就算在訓練集上正確率100%,也不能說明它刻畫了真實的數據分布,要知道刻畫真實的數據分布才是我們的目的,而不是只刻畫訓練集的有限的數據點)。而且,實際中,訓練樣本往往還有一定的噪音誤差,所以如果太追求在訓練集上的完美而采用一個很復雜的模型,會使得模型把訓練集裡面的誤差都當成了真實的數據分布特征,從而得到錯誤的數據分布估計。這樣的話,到了真正的測試集上就錯的一塌糊塗了(這種現像叫過擬合)。但是也不能用太簡單的模型,否則在數據分布比較復雜的時候,模型就不足以刻畫數據分布了(體現為連在訓練集上的錯誤率都很高,這種現像較欠擬合)。過擬合表明采用的模型比真實的數據分布更復雜,而欠擬合表示采用的模型比真實的數據分布要簡單。
在統計學習框架下,大家刻畫模型復雜度的時候,有這麼個觀點,認為Error = Bias + Variance。這裡的Error大概可以理解為模型的預測錯誤率,是有兩部分組成的,一部分是由於模型太簡單而帶來的估計不准確的部分(Bias),另一部分是由於模型太復雜而帶來的更大的變化空間和不確定性(Variance)。
所以,這樣就容易分析樸素貝葉斯了。它簡單的假設了各個數據之間是無關的,是一個被嚴重簡化了的模型。所以,對於這樣一個簡單模型,大部分場合都會Bias部分大於Variance部分,也就是說高偏差而低方差。
在實際中,為了讓Error盡量小,我們在選擇模型的時候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
偏差和方差與模型復雜度的關系使用下圖更加明了: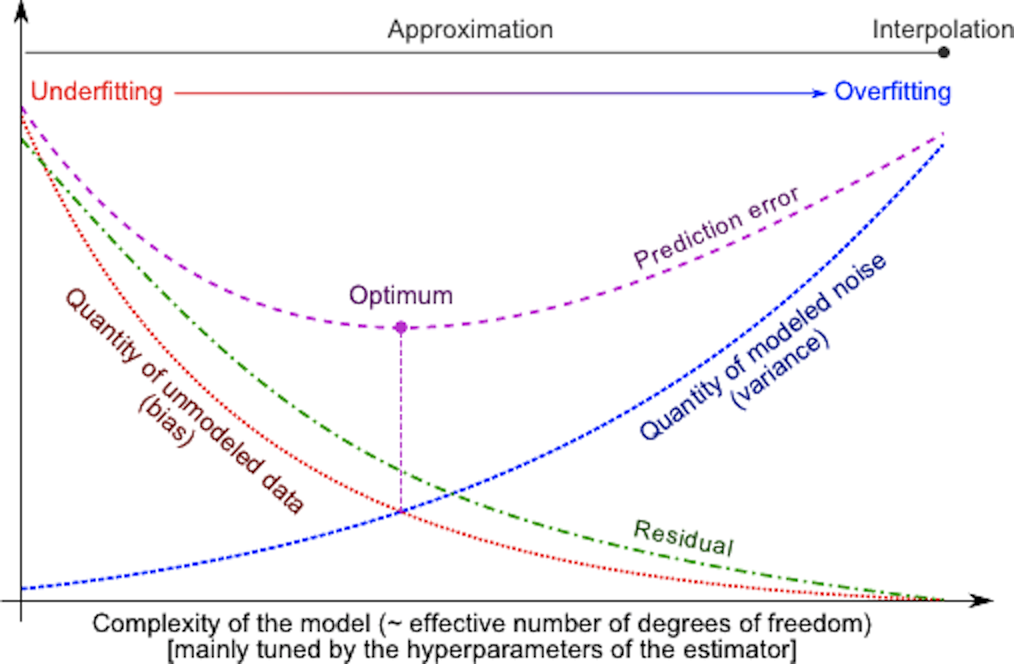
當模型復雜度上升的時候,偏差會逐漸變小,而方差會逐漸變大。
事件A和B同時發生的概率為在A發生的情況下發生B或者在B發生的情況下發生A。
所以有:
對於給出的待分類項,求解在此項出現的條件下各個目標類別出現的概率,哪個最大,就認為此分類項屬於哪個類別。
當某個類別下某個特征劃分沒有出現時,會有,就是導致分類器質量降低,所以此時引入Laplace校驗,就是對沒類別下所有劃分的計數加1。
參考改進的貝葉斯網絡,使用DAG來進行概率圖的描述
邏輯回歸(LR)是一個線性的二分類模型,主要是計算在某個樣本特征下事件發生的概率,比如根據用戶的瀏覽購買情況作為特征來計算它是否會購買這個商品,抑或是它是否會點擊這個商品。然後LR的最終值是根據一個線性和函數再通過一個sigmoid函數來求得,這個線性和函數權重與特征值的累加以及加上偏置求出來的,所以在訓練LR時也就是在訓練線性和函數的各個權重值w。
where
其導數形式為:
邏輯回歸方法主要是用最大似然估計來學習的,所以單個樣本的後驗概率為:
到整個樣本的後驗概率為:
其中:
通過對數進一步化簡為:
其實它的損失函數(Loss Function)為,因此我們需使Loss Function最小,可採用梯度下降法得到。梯度下降法公式為:
其中α為步長,直到不能再小時停止
梯度下降法的最大問題就是會陷入局部最優,並且每次在對當前樣本計算cost的時候都需要去遍歷全部樣本才能得到cost值,這樣計算速度就會慢很多(雖然在計算的時候可以轉為矩陣乘法去更新整個w值)
所以現在好多框架(mahout)中一般使用隨機梯度下降法,它在計算cost的時候只計算當前的代價,最終cost是在全部樣本迭代一遍之求和得出,還有他在更新當前的參數w的時候並不是依次遍歷樣本,而是從所有的樣本中隨機選擇一條進行計算,它方法收斂速度快(一般是使用最大迭代次數),並且還可以避免局部最優,並且還很容易並行(使用參數服務器的方式進行並行)
優缺點:無需選擇學習率α,更快,但是更複雜
線性回歸才是真正用於回歸的,而不像logistic回歸是用於分類,其基本思想是用梯度下降法對最小二乘法形式的誤差函數進行優化,當然也可以用normal equation直接求得參數的解,結果為:
而在LWLR(局部加權線性回歸)中,參數的計算表達式為:
因為此時優化的是:
由此可見LWLR與LR不同,LWLR是一個非參數模型,因為每次進行回歸計算都要遍歷訓練樣本至少一次。
總之, logistic回歸與線性回歸實際上有很多相同之處,最大的區別就在於他們的因變量不同,其他的基本都差不多,正是因為如此,這兩種回歸可以歸於同壹個家族,即廣義線性模型(generalized linear model)。這一家族中的模型形式基本上都差不多,不同的就是因變量不同,如果是連續的,就是多重線性回歸,如果是二項分布,就是logistic回歸。logistic回歸的因變量可以是二分類的,也可以是多分類的,但是二分類的更為常用,也更加容易解釋。所以實際中最為常用的就是二分類的logistic回歸。
KNN即最近鄰算法,其主要過程為:
如何選擇一個最佳的K值,這取決於數據。一般情況下,在分類時較大的K值能夠減小噪聲的影響。但會使類別之間的界限變得模糊。一個較好的K值可通過各種啟發式技術來獲取,比如,交叉驗證。另外噪聲和非相關性特征向量的存在會使K近鄰算法的准確性減小。
近鄰算法具有較強的一致性結果。隨著數據趨於無限,算法保證錯誤率不會超過貝葉斯算法錯誤率的兩倍。對於一些好的K值,K近鄰保證錯誤率不會超過貝葉斯理論誤差率。
所以一般k會取一個較小的值,然後用過交叉驗證來確定。
這裡所謂的交叉驗證就是將樣本劃分一部分出來為預測樣本,比如95%訓練,5%預測,然後K分別取1,2,3,4,5之類的,進行預測,計算最後的分類誤差,選擇誤差最小的K。
在找到最近的k個實例之後,可以計算這k個實例的平均值作為預測值。或者還可以給這k個實例添加一個權重再求平均值,這個權重與度量距離成反比(越近權重越大)。
KD樹是一個二叉樹,表示對K維空間的一個劃分,可以進行快速檢索(那KNN計算的時候不需要對全樣本進行距離的計算了)。
在k維的空間上循環找子區域的中位數進行劃分的過程。
假設現在有K維空間的數據集
通過KD樹的搜索找到與搜索目標最近的點,這樣KNN的搜索就可以被限制在空間的局部區域上了,可以大大增加效率。
當實例隨機分布的時候,搜索的復雜度為log(N),N為實例的個數,KD樹更加適用於實例數量遠大於空間維度的KNN搜索,如果實例的空間維度與實例個數差不多時,它的效率基於等於線性掃描。
對於樣本點以及svm的超平面:
svm的基本想法就是求解能正確劃分訓練樣本並且其幾何間隔最大化的超平面。
先來看SVM的問題:
那麼假設
則將問題轉為:
由於γ̂的成比例增減不會影響實際間距,所以這裡的取γ̂ =1,又因為
所以最終的問題就變為了
這樣就變成了一個凸的二次規劃化,可以將其轉換為拉格朗日函數,然後使用對偶算法來求解
引進拉格朗日乘子,定義拉格朗日函數:
根據對偶性質 原始問題就是求對偶問題的極大極小
先求L對w,b的極小,再求對α的極大。
求,也就是相當於對w,b求偏導並且另其等於0
代入後可得
求對α的極大,即是對偶問題:
將求最大轉為求最小,得到等價的式子為:
假如求解出來的α為
則得到最優的w,bw,b分別為
所以,最終的決策分類面為
也就是說,分類決策函數只依賴於輸入xx與訓練樣本的輸入的內積。
ps:上面介紹的是SVM的硬間距最大化,還有一種是軟間距最大化,引用了松弛變量ζ,則SVM問題變為:
其余解決是與硬間距的一致。
還有:與分離超平面最近的樣本點稱為支持向量。
損失函數為(優化目標):
其中稱為折頁損失函數,因為:
將輸入特征x(線性不可分)映射到高維特征R空間,可以在R空間上讓SVM進行線性可以變,這就是核函數的作用
對於核函數的選擇也是有技巧的(libsvm中自帶了四種核函數:線性核、多項式核、RBF核以及Sigmoid核):
SMO是用於快速求解SVM的。
它選擇凸二次規劃的兩個變量,其他的變量保持不變,然後根據這兩個變量構建一個二次規劃問題,這個二次規劃關於這兩個變量解會更加的接近原始二次規劃的解,通過這樣的子問題劃分可以大大增加整個算法的計算速度,關於這兩個變量:
決策樹是一顆依托決策而建立起來的樹。
一個屬性中某個類別的熵表示
情況下發生
的概率,也即是統計概率。
整個屬性的熵,為各個類別的比例與各自熵的加權求和。
Gain(C,A)=S(C)−S(C,A)
增益表示分類目標的熵減去當前屬性的熵,增益越大,分類能力越強
(這裡前者叫做經驗熵,表示數據集分類C的不確定性,後者就是經驗條件熵,表示在給定A的條件下對數據集分類C的不確定性,兩者相減叫做互信息,決策樹的增益等價於互信息)。
關於損失函數
設樹的葉子節點個數為T,t為其中一個葉子節點,該葉子節點有個樣本,其中k類的樣本有
個,H(t)為葉子節點上的經驗熵,則損失函數定義為
其中
代入可以得到
λ|T|為正則化項,λ是用於調節比率
決策樹的生成只考慮了信息增益
它是ID3的一個改進算法,使用信息增益率來進行屬性的選擇
優缺點:
准確率高,但是子構造樹的過程中需要進行多次的掃描和排序,所以它的運算效率較低
分類回歸樹(Classification And Regression Tree)是一個決策二叉樹,在通過遞歸的方式建立,每個節點在分裂的時候都是希望通過最好的方式將剩余的樣本劃分成兩類,這裡的分類指標:
分類樹:
gini用來度量分布不均勻性(或者說不純),總體的類別越雜亂,gini指數就越大(跟熵的概念很相似)當前數據集中第i類樣本的比例
gini越小,表示樣本分布越均勻(0的時候就表示只有一類了),越大越不均勻
基尼增益
表示當前屬性的一個混亂,表示當前類別占所有類別的概率。
最終Cart選擇GiniGain最小的特征作為劃分特征。
回歸樹:
回歸樹是以平方誤差最小化的准則劃分為兩塊區域
這裡面的最小化我記得可以使用最小二乘法來求
關於剪枝:用獨立的驗證數據集對訓練集生長的樹進行剪枝(事後剪枝)。
隨機森林是有很多隨機得決策樹構成,它們之間沒有關聯。得到RF以後,在預測時分別對每一個決策樹進行判斷,最後使用Bagging的思想進行結果的輸出(也就是投票的思想)。
一般很多的決策樹算法都一個重要的步驟——剪枝,但隨機森林不這樣做,由於之前的兩個隨機采樣的過程保證了隨機性,所以就算不剪枝,也不會出現over-fitting。 按這種算法得到的隨機森林中的每一棵都是很弱的,但是大家組合起來就很厲害了。可以這樣比喻隨機森林算法:每一棵決策樹就是一個精通於某一個窄領域的專家(因為我們從M個feature中選擇m讓每一棵決策樹進行學習),這樣在隨機森林中就有了很多個精通不同領域的專家,對一個新的問題(新的輸入數據),可以用不同的角度去看待它,最終由各個專家,投票得到結果。
使用oob(out-of-bag)進行泛化誤差的估計,將各個樹的未采樣樣本作為預測樣本(大約有36.8%),使用已經建立好的森林對各個預測樣本進行預測,預測完之後最後統計誤分得個數占總預測樣本的比率作為RF的oob誤分率。
Cart可以通過特征的選擇迭代建立一顆分類樹,使得每次的分類平面能最好的將剩余數據分為兩類,表示每個類別出現的概率和與1的差值。
分類問題:argmax(Gini−GiniLeft−GiniRight)
回歸問題:argmax(Var−VarLeft−VarRight)
查找最佳特征f已經最佳屬性閾值th 小於th的在左邊,大於th的在右邊子樹
模型生成
令n為訓練數據的實例數量
對於t次循環中的每一次
從訓練數據中采樣n個實例
將學習應用於所采樣本
保存結果模型
分類
對於t個模型的每一個
使用模型對實例進行預測
返回被預測次數最多的一個
bagging:bootstrap aggregating的縮寫。讓該學習算法訓練多輪,每輪的訓練集由從初始的訓練集中隨機取出的n個訓練樣本組成,某個初始訓練樣本在某輪訓練集中可以出現多次或根本不出現,訓練之後可得到一個預測函數序列
最終的預測函數H對分類問題采用投票方式,對回歸問題采用簡單平均方法對新示例進行判別。
[訓練R個分類器f_i,分類器之間其他相同就是參數不同。其中f_i是通過從訓練集合中(N篇文檔)隨機取(取後放回)N次文檔構成的訓練集合訓練得到的。對於新文檔d,用這R個分類器去分類,得到的最多的那個類別作為d的最終類別。]
模型生成
賦予每個訓練實例相同的權值
t次循環中的每一次:
將學習算法應用於加了權的數據集上並保存結果模型
計算模型在加了權的數據上的誤差e並保存這個誤差
結果e等於0或者大於等於0.5:
終止模型
對於數據集中的每個實例:
如果模型將實例正確分類
將實例的權值乘以e/(1-e)
將所有的實例權重進行正常化
分類
賦予所有類權重為0
對於t(或小於t)個模型中的每一個:
給模型預測的類加權 -log(e/(1-e))
返回權重最高的類
boosting: 其中主要的是AdaBoost(Adaptive boosting,自適應boosting)。初始化時對每一個訓練例賦相等的權重1/N,然後用該學算法對訓練集訓練t輪,每次訓練後,對訓練失敗的訓練例賦以較大的權重,也就是讓學習算法在後續的學習中集中對比較難的訓練例進行學習,從而得到一個預測函數序列h1,⋯,hmh1,⋯,hm , 其中h_i也有一定的權重,預測效果好的預測函數權重較大,反之較小。最終的預測函數H對分類問題采用有權重的投票方式,對回歸問題采用加權平均的方法對新示例進行判別。
提升算法理想狀態是這些模型對於其他模型來說是一個補充,每個模型是這個領域的一個專家,而其他模型在這部分卻不能表現很好,就像執行官一樣要尋覓那些技能和經驗互補的顧問,而不是重復的。這與裝袋算法有所區分。
模型生成
訓練數據中的每個樣本,並賦予一個權重,構成權重向量D,初始值為1/N
t次循環中的每一次:
在訓練數據上訓練弱分類器並計算分類器的錯誤率e
如果e等於0或者大於等於用戶指定的閾值:
終止模型,break
重新調整每個樣本的權重,其中alpha=0.5*ln((1-e)/e)
對權重向量D進行更新,正確分類的樣本的權重降低而錯誤分類的樣本權重值升高
對於數據集中的每個樣例:
如果某個樣本正確分類:
權重改為D^(t+1)_i = D^(t)_i * e^(-a)/Sum(D)
如果某個樣本錯誤分類:
權重改為D^(t+1)_i = D^(t)_i * e^(a)/Sum(D)
分類
賦予所有類權重為0
對於t(或小於t)個模型(基分類器)中的每一個:
給模型預測的類加權 -log(e/(1-e))
返回權重最高的類
(類似Bagging方法,但是訓練是串行進行的,第k個分類器訓練時關注對前k-1分類器中錯分的文檔,即不是隨機取,而是加大取這些文檔的概率。)
GBDT的精髓在於訓練的時候都是以上一顆樹的殘差為目標,這個殘差就是上一個樹的預測值與真實值的差值。
Gradient boosting(又叫Mart, Treenet):Boosting是一種思想,Gradient Boosting是一種實現Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型損失函數的梯度下降方向。損失函數(loss function)描述的是模型的不靠譜程度,損失函數越大,則說明模型越容易出錯。如果我們的模型能夠讓損失函數持續的下降,則說明我們的模型在不停的改進,而最好的方式就是讓損失函數在其梯度(Gradient)的方向上下降。
Boosting的好處就是每一步的參加就是變相了增加了分錯instance的權重,而對已經對的instance趨向於0,這樣後面的樹就可以更加關注錯分的instance的訓練了
Shrinkage認為,每次走一小步逐步逼近的結果要比每次邁一大步逼近結果更加容易避免過擬合。
就像我們做互聯網,總是先解決60%用戶的需求湊合著,再解決35%用戶的需求,最後才關注那5%人的需求,這樣就能逐漸把產品做好。
k-Means算法是一種聚類算法,它是一種無監督學習算法,目的是將相似的對像歸到同一個蔟中。蔟內的對像越相似,聚類的效果就越好。聚類和分類最大的不同在於,分類的目標事先已知,而聚類則不一樣。其產生的結果和分類相同,而只是類別沒有預先定義。
設計的目的:使各個樣本與所在類均值的誤差平方和達到最小(這也是評價K-means算法最後聚類效果的評價標准)
創建k個點作為K個簇的起始質心(經常隨機選擇)
當任意一個點的蔟分配結果發生變化時(初始化為True)
對數據集中的每個數據點,重新分配質心
對每個質心
計算質心到數據點之間的距離
將數據點分配到距其最近的蔟
對每個蔟,計算蔟中所有點的均值並將均值作為新的質心
K-Means算法K值如何選擇?
《大數據》中提到:給定一個合適的類簇指標,比如平均半徑或直徑,只要我們假設的類簇的數目等於或者高於真實的類簇的數目時,該指標上升會很緩慢,而一旦試圖得到少於真實數目的類簇時,該指標會急劇上升。
1) 簇的直徑是指簇內任意兩點之間的最大距離。
2) 簇的半徑是指簇內所有點到簇中心距離的最大值。
如何優化K-Means算法搜索的時間復雜度?
可以使用K-D樹來縮短最近鄰的搜索時間(NN算法都可以使用K-D樹來優化時間復雜度)。
如何確定K個簇的初始質心?
1) 選擇批次距離盡可能遠的K個點
首先隨機選擇一個點作為第一個初始類簇中心點,然後選擇距離該點最遠的那個點作為第二個初始類簇中心點,然後再選擇距離前兩個點的最近距離最大的點作為第三個初始類簇的中心點,以此類推,直至選出K個初始類簇中心點。
2) 選用層次聚類或者Canopy算法進行初始聚類,然後利用這些類簇的中心點作為KMeans算法初始類簇中心點。
聚類擴展:密度聚類、層次聚類。
EM用於隱含變量的概率模型的極大似然估計,它一般分為兩步:
第一步求期望(E),選取一組參數,求出在該參數下隱含變量的條件概率值;
第二步求極大(M),結合E步求出的隱含變量條件概率,求出似然函數下界函數(本質上是某個期望函數)的最大值。
重複上面2步直至收斂。
如果概率模型的變量都是觀測變量,那麼給定數據之後就可以直接使用極大似然法或者貝葉斯估計模型參數。
但是當模型含有隱含變量的時候就不能簡單的用這些方法來估計,EM就是一種含有隱含變量的概率模型參數的極大似然估計法。
應用到的地方:混合高斯模型、混合樸素貝葉斯模型、因子分析模型。
(E Step) For each i, set
(M Step) set
M步公式中下界函數的推導過程:
EM算法一個常見的例子就是GMM模型,每個樣本都有可能由k個高斯產生,只不過由每個高斯產生的概率不同而已,因此每個樣本都有對應的高斯分布(k個中的某一個),此時的隱含變量就是每個樣本對應的某個高斯分布。
GMM的E步公式如下(計算每個樣本對應每個高斯的概率):
(E Step) For each i, j, set
更具體的計算公式為:
M步公式如下(計算每個高斯的比重,均值,方差這3個參數):
(M Step) Update the parameters:
關於EM算法可以參考Ng的CS229課程資料或者斯坦福機器學習公開課
另外,參考另一篇文章——從最大似然到EM算法淺解
Apriori是關聯分析中比較早的一種方法,主要用來挖掘那些頻繁項集合。其思想是:
FP Growth是一種比Apriori更高效的頻繁項挖掘方法,它只需要掃描項目表2次。其中第1次掃描獲得當個項目的頻率,去掉不符合支持度要求的項,並對剩下的項排序。第2遍掃描是建立一顆FP-Tree(frequent-patten tree)。
在機器學習中往往是最終要求解某個函數的最優值,但是一般情況下,任意一個函數的最優值求解比較困難,但是對於凸函數來說就可以有效的求解出全局最優值。
一個集合C是,當前僅當任意x,y屬於C且0≦Θ≦1,都有Θ∗x+(1−Θ)∗yΘ∗x+(1−Θ)∗y屬於C。
用通俗的話來說C集合線段上的任意兩點也在C集合中
一個函數f其定義域(D(f))是凸集,並且對任意x,y屬於D(f)和0≦Θ≦1都有
f(Θ∗x+(1−Θ)∗y)≦Θ∗f(x)+(1−Θ)∗f(y)
用通俗的話來說就是曲線上任意兩點的割線都在曲線的上方。
常見的凸函數有:
凸函數的判定:
凸優化應用舉例
可以估計樣本的密度函數,對於新樣本直接計算其密度,如果密度值小於某一閾值,則表示該樣本異常。而密度函數一般采用多維的高斯分布。如果樣本有n維,則每一維的特征都可以看作是符合高斯分布的,即使這些特征可視化出來不太符合高斯分布,也可以對該特征進行數學轉換讓其看起來像高斯分布,比如說x=log(x+c), x=x^(1/c)等。異常檢測的算法流程如下:
Anomaly detection algorithm
其中的ε也是通過交叉驗證得到的,也就是說在進行異常檢測時,前面的p(x)的學習是用的無監督,後面的參數ε學習是用的有監督。那麼為什麼不全部使用普通有監督的方法來學習呢(即把它看做是一個普通的二分類問題)?主要是因為在異常檢測中,異常的樣本數量非常少而正常樣本數量非常多,因此不足以學習到好的異常行為模型的參數,因為後面新來的異常樣本可能完全是與訓練樣本中的模式不同。
另外,上面是將特征的每一維看成是相互獨立的高斯分布,其實這樣的近似並不是最好的,但是它的計算量較小,因此也常被使用。更好的方法應該是將特征擬合成多維高斯分布,這時有特征之間的相關性,但隨之計算量會變復雜,且樣本的協方差矩陣還可能出現不可逆的情況(主要在樣本數比特征數小,或者樣本特征維數之間有線性關系時)。
上面的內容可以參考Ng的斯坦福機器學習公開課
之前翻譯過一些國外的文章,有一篇文章中給出了一個簡單的算法選擇技巧:
通常情況下:【GBDT>=SVM>=RF>=Adaboost>=Other…】,現在深度學習很熱門,很多領域都用到,它是以神經網絡為基礎的,目前我自己也在學習,只是理論知識不是很厚實,理解的不夠深,這裡就不做介紹了。
算法固然重要,但好的數據卻要優於好的算法,設計優良特征是大有裨益的。假如你有一個超大數據集,那麼無論你使用哪種算法可能對分類性能都沒太大影響(此時就可以根據速度和易用性來進行抉擇)。
Reference: